In het afgelopen decennium heeft JSON zich gevestigd als de standaardindeling voor web-API’s en microservices. De toenemende complexiteit en omvang van data hebben echter geleid tot de ontwikkeling van alternatieven voor JSON; serialisatieformaten die zijn afgestemd op specifieke eisen.
Dit artikel biedt een overzicht van verschillende opkomende formaten die het afgelopen jaar steeds meer aan populariteit en relevantie hebben gewonnen.
JSON
JavaScript Object Notation (JSON) werd begin jaren 2000 geïntroduceerd als een eenvoudig, tekstgebaseerd formaat voor data uitwisseling. De eenvoud, de leesbaarheid voor mensen en de brede compatibiliteit met diverse programmeertalen droegen bij aan de snelle adoptie ervan als standaard voor het verzenden van gestructureerde data tussen servers en cliënten. Ondanks het brede gebruik vandaag de dag kent JSON verschillende beperkingen:
Inefficiënte opslag: Als tekstgebaseerd formaat zijn JSON-bestanden doorgaans groter dan hun binaire tegenhangers, wat kan leiden tot hogere opslagvereisten en bandbreedteverbruik.
Verwerkingskosten (parsing overhead): Het verwerken van JSON gaat over het algemeen langzamer dan bij binaire formaten, waardoor het minder geschikt is voor toepassingen die hoge prestaties vereisen.
Ontbreken van schema-ondersteuning: JSON bevat geen ingebouwde mechanismen voor schema-validatie, wat kan leiden tot inconsistenties bij het beheren van grote of complexe datasets.
Dataredundantie: Herhaalde veldnamen binnen grote datasets zorgen voor onnodige opslagoverhead.
Deze factoren hebben geleid tot de ontwikkeling en adoptie van alternatieve serialisatieformaten zoals Apache Parquet, Avro, Protocol Buffers en ORC. Elk van deze formaten richt zich op specifieke uitdagingen die zich voordoen in moderne data managementomgevingen.
Vergelijking van nieuwe dataformaten
Apache Parquet
Structuur: Kolomgebaseerd opslagformaat
Voordelen: Geoptimaliseerd voor leesintensieve analytische workloads, met efficiënte compressie- en coderingsmethoden die de prestaties verbeter
Typische gebruiksscenario’s: Geschikt voor complexe queries en aggregaties, vaak toegepast in datawarehousing en business intelligence omgevingen
Industrieel gebruik: Breed ingezet door big data platforms zoals Apache Spark, Google BigQuery en Amazon Redshift
Apache Avro
Structuur: Rij-gebaseerd opslagformaat
Voordelen: Sterke ondersteuning voor schema-evolutie gecombineerd met compacte binaire codering voor efficiënte serialisatie
Typische gebruiksscenario’s: Geschikt voor schrijfintensieve transactionele workloads en situaties die frequente schemawijzigingen vereisen, zoals logverwerking en streaming datapijplijnen
Industrieel gebruik: Gebruikt door organisaties zoals LinkedIn voor data-serialisatie en communicatie tussen services
Protocol Buffers
Structuur: Binair serialisatieformaat
Voordelen: Biedt compacte en snelle serialisatie, met ingebouwde ondersteuning voor schema-evolutie en backward/forward compatibiliteit
Typische gebruiksscenario’s: Veel gebruikt voor communicatie tussen services in gRPC-gebaseerde microservices en mobiele applicaties waar lage latency belangrijk is
Industrieel gebruik: Uitgebreid toegepast door Google en diverse gedistribueerde systemen en cloudapplicaties
Optimized Row Columnar (ORC)
Structuur: Kolomgebaseerd opslagformaat
Voordelen: Biedt hoge compressieverhoudingen en geoptimaliseerde leesprestaties, specifiek ontworpen voor leesintensieve workloads
Typische gebruiksscenario’s: Vaak toegepast in datawarehousing-scenario’s die snelle lees-toegang en complexe analytische queries vereisen
Industrieel gebruik: Voornamelijk gebruikt binnen het Apache Hive-ecosysteem voor efficiënte dataopslag en -querying
JSON versus moderne formaten
Om de relatieve voordelen van verschillende serialisatieformaten te illustreren, is een benchmark uitgevoerd met een dataset van 100.000 records, bestaande uit een basis gebruikersentiteit. De benchmark meet de lees- en schrijfprestaties van verschillende formaten.
De onderstaande samenvatting geeft een overzicht van de prestaties van elk formaat onder belasting en biedt handvatten om de meest geschikte oplossing te kiezen op basis van specifieke vereisten.
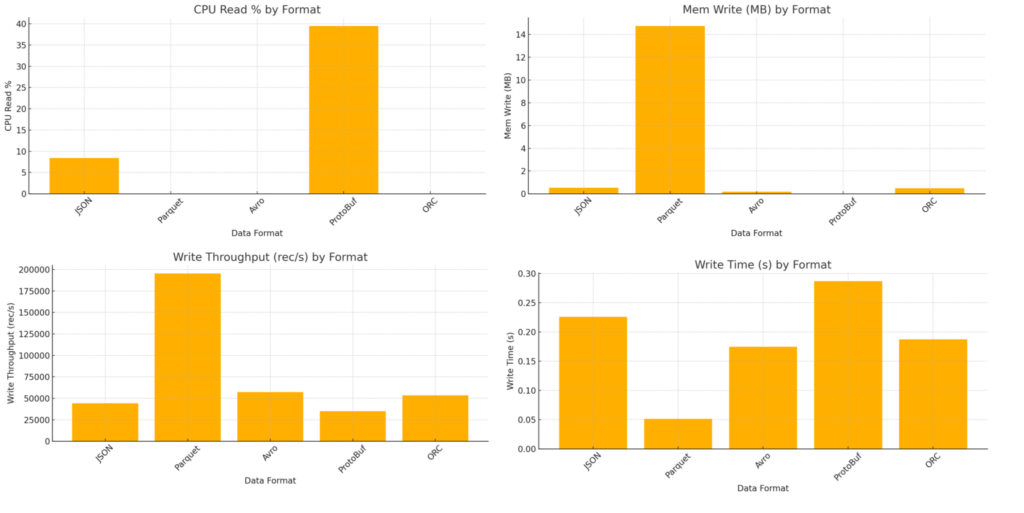
Read Operations Benchmark
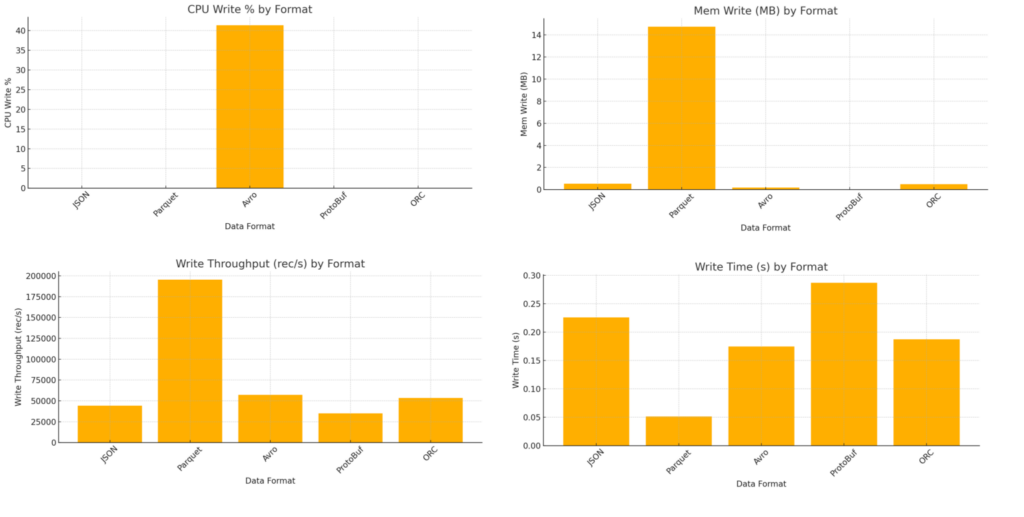
Write Operations Benchmark
Samenvatting van de resultaten
Protocol Buffers (ProtoBuf) toonde de hoogste leesprestaties met een doorvoersnelheid van ongeveer 897.000 records per seconde. Het binaire formaat zorgt voor snelle deserialisatie, wat het zeer geschikt maakt voor realtime applicaties en microservices. Opmerkelijk was dat CPU- en geheugengebruik tijdens schrijfoperaties minimaal leken, mogelijk door de efficiëntie van het formaat of beperkingen in de meetperiode.
Apache Avro en Apache Parquet leverden sterke en consistente prestaties. Parquet is dankzij het kolomgebaseerde ontwerp geoptimaliseerd voor leesintensieve analytische workloads, met effectieve compressie en goede leesdoorvoer. Avro excelleerde in schrijfsnelheid en handhaafde tegelijkertijd een redelijke leesprestaties. De ondersteuning voor schema-evolutie en de rij-gebaseerde structuur maken het bijzonder geschikt voor streaming datapijplijnen.
Optimized Row Columnar (ORC) bood een evenwichtige lees- en schrijfprestaties, maar had iets hoger geheugenverbruik. ORC is gericht op big data-omgevingen, vooral in combinatie met Apache Hive. De beperkte ondersteuning voor schema-evolutie kan echter een nadeel zijn ten opzichte van Avro of ProtoBuf.
JSON, ondanks zijn menselijke leesbaarheid, had de laagste prestaties wat betreft bestandsgrootte-efficiëntie en verwerkingssnelheid. Het vertoonde aanzienlijk lagere doorvoersnelheden en grotere bestanden, wat de beperkingen bevestigt voor toepassingen die hoge prestaties of opslagoptimalisatie vereisen.
Belangrijkste conclusies
JSON is af te raden in situaties waar prestaties en opslagefficiëntie van cruciaal belang zijn.
Voor toepassingen waarbij snelheid en compacte data voorop staan, is Protocol Buffers het aanbevolen formaat, vooral in systemen waar lage latency essentieel is.
Voor data lakes en analytische workloads zijn Parquet en ORC aan te bevelen vanwege hun compressie en kolomgebaseerde opslag.
Avro blijft een sterke keuze voor logverwerking en Kafka-gebaseerde streaming systemen, dankzij de ondersteuning voor schema-evolutie.
Opkomende dataformaten
Naast de eerder besproken, breed toegepaste serialisatieformaten, winnen verschillende opkomende formaten terrein binnen specifieke domeinen. Deze formaten streven naar een balans tussen prestaties, efficiëntie en compatibiliteit, vaak gericht op nichetoepassingen zoals embedded systemen, realtime communicatie of documentdatabases.
BSON (Binary JSON): Voornamelijk gebruikt in MongoDB, breidt BSON het JSON-datamodel uit door ondersteuning voor extra datatypes toe te voegen, zoals binaire data en datumformaten. Dit maakt efficiëntere opslag en terugwinning mogelijk, terwijl de compatibiliteit met JSON-structuren behouden blijft.
MessagePack: Een compact binair serialisatieformaat dat de datasize verkleint zonder in te boeten aan verwerkingssnelheid. Dankzij het lichte karakter is het goed geschikt voor netwerktransmissie en mobiele of resource-beperkte omgevingen.
CBOR (Concise Binary Object Representation): Ontworpen voor kleinschalige en embedded systemen, biedt CBOR efficiënte serialisatie van datastructuren met focus op een minimale footprint en lage verwerkingsbelasting. Het wordt veel toegepast in IoT-toepassingen.
UBJSON (Universal Binary JSON): Geïntroduceerd als een universele binaire representatie van JSON, behoudt UBJSON een nauwe aansluiting bij de JSON-specificatie en levert het verbeterde prestaties en opslag efficiëntie. Het richt zich op het bieden van een consistente en efficiënte alternatieve binare serialisatie met JSON-compatibiliteit.
Conclusie
De toenemende eisen van big data en prestatiekritische toepassingen hebben de beperkingen van JSON duidelijk gemaakt, wat heeft geleid tot de adoptie van efficiëntere en gespecialiseerde serialisatieformaten. Hoewel JSON voor veel scenario’s nog steeds een praktische keuze is, vooral wanneer leesbaarheid en eenvoud belangrijk zijn, is het minder geschikt voor omgevingen waarin schaalbaarheid, snelheid en opslagoptimalisatie cruciaal zijn.
Door inzicht te krijgen in de sterke punten en afwegingen van alternatieven voor JSON, zoals Protocol Buffers, Avro, Parquet en anderen, kunnen organisaties beter onderbouwde keuzes maken die aansluiten bij hun technische en operationele behoeften. Naarmate de hoeveelheid data en de verwerkingsvereisten toenemen, zal het bijblijven met de ontwikkelingen in serialisatietechnologieën essentieel zijn voor het behouden van effectieve en efficiënte datamanagementpraktijken.
Neem contact op
Deel dit artikel
Author
NetRom Software
NetRom Software bestaat uit een divers team van domeinexperts en hoogopgeleide developers in Roemenië. Met diepgaande technische kennis en praktijkervaring delen onze specialisten regelmatig inzichten over softwareontwikkeling, digitale innovatie en best practices uit de sector. Door onze expertise te delen, streven we naar samenwerking, transparantie en continue verbetering.