Over the past decade, JSON has established itself as the primary format for web APIs and microservices. However, growing data complexity and volume have led to the development of alternatives to JSON; serialization formats tailored to specific requirements.
This article provides an overview of several emerging formats that have gained increased adoption and relevance in the last year.
JSON
JavaScript Object Notation (JSON) was introduced in the early 2000s as a lightweight, text-based format for data interchange. Its simplicity, ease of human readability, and broad compatibility with various programming languages contributed to its rapid adoption as a standard for transmitting structured data between servers and clients. Despite its widespread use today, JSON has several limitations:
Inefficient storage: As a text-based format, JSON files tend to be larger than their binary counterparts, which can increase storage requirements and bandwidth consumption.
Parsing overhead: The process of parsing JSON is generally slower compared to binary formats, making it less efficient for applications requiring high-performance data processing.
Lack of schema support: JSON does not include built-in mechanisms for schema validation, which can result in inconsistencies when managing large or complex datasets.
Data redundancy: Repeated field names within large datasets can lead to unnecessary storage overhead.
These factors have prompted the development and adoption of alternative serialization formats such as Apache Parquet, Avro, Protocol Buffers, and ORC. Each of these formats addresses specific challenges encountered in contemporary data management environments.
Comparing new data formats
Selecting an appropriate serialization format is a critical decision that impacts storage strategies, data processing, and the scalability of systems over time. Beyond performance considerations, it is important to understand the design goals of each format, their typical applications, and how their features align with specific use cases.
Apache Parquet
Structure: Columnar storage format
Advantages: Optimized for read-intensive analytical workloads, with efficient data compression and encoding methods that improve performance
Typical use cases: Suitable for complex queries and aggregations, commonly employed in data warehousing and business intelligence environments
Industry adoption: Widely utilized by big data platforms such as Apache Spark, Google BigQuery, and Amazon Redshift
Apache Avro
Structure: Row-based storage format
Advantages: Strong support for schema evolution combined with compact binary encoding for efficient serialization
Typical use cases: Well suited for write-heavy transactional workloads and use cases requiring frequent schema changes, such as log processing and streaming data pipelines
Industry adoption: Adopted by organizations including LinkedIn for data serialization and inter-service communication
Protocol Buffers
Structure: Binary serialization format
Advantages: Provides compact and fast serialization, with built-in support for schema evolution and backward/forward compatibility
Typical use cases: Commonly used for inter-service communication in gRPC-based microservices and mobile applications where low-latency data transmission is important
Industry adoption: Extensively used by Google and various distributed systems and cloud applications
Optimized Row Columnar (ORC)
Structure: Columnar storage format
Advantages: Offers high compression ratios and optimized read performance, designed specifically for read-intensive workloads
Typical use cases: Frequently applied in data warehousing scenarios that require rapid read access and complex analytical queries
Industry adoption: Primarily used within the Apache Hive ecosystem for efficient data storage and querying
JSON vs. modern formats
To illustrate the relative advantages of various serialization formats, a benchmark was conducted using a dataset of 100,000 records representing a basic user entity. The benchmark measured read and write performance across different formats.
The following summary provides an overview of how each format performs under load and offers guidance for selecting the most appropriate solution based on specific requirements.
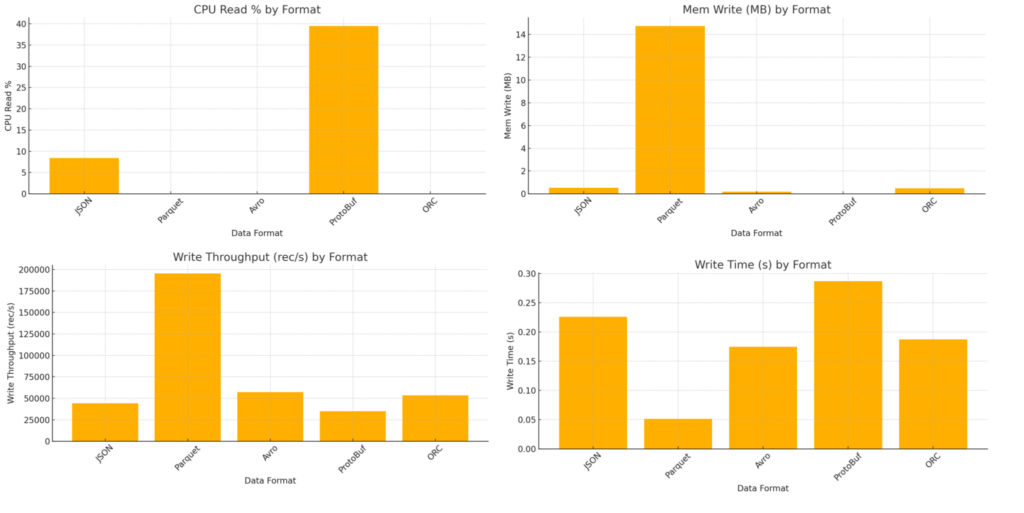
Read Operations Benchmark
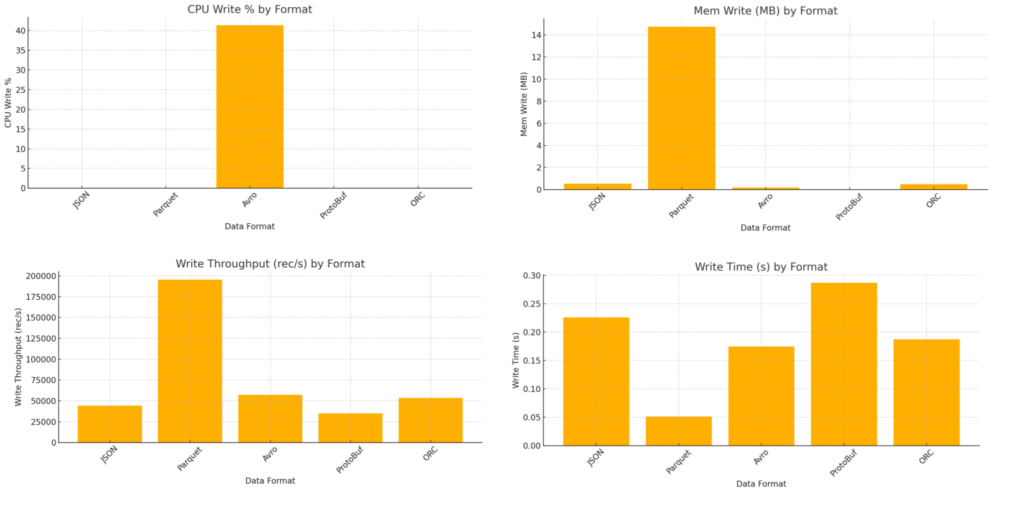
Write Operations Benchmark
Summary of results
Protocol Buffers (ProtoBuf) demonstrated the highest read performance, achieving a throughput of approximately 897,000 records per second. Its binary format facilitates rapid deserialization, making it well-suited for real-time applications and microservices. Notably, CPU and memory usage during write operations appeared minimal, possibly due to the efficiency of the format or limitations in the measurement interval.
Apache Avro and Apache Parquet delivered strong and consistent performance. Parquet, with its columnar design, is optimized for read-heavy analytical workloads, providing effective compression and good read throughput. Avro showed superior write performance while maintaining moderate read speeds. Its support for schema evolution and row-based structure make it particularly suitable for streaming data pipelines.
Optimized Row Columnar (ORC) offered balanced read and write performance, though it exhibited slightly higher memory usage. ORC is tailored for big data environments, especially when integrated with Apache Hive. However, its limited support for schema evolution may be a disadvantage compared to Avro or ProtoBuf.
JSON, while human-readable, showed the lowest performance in terms of file size efficiency and processing speed. It recorded significantly lower throughput and larger file sizes, confirming its limitations for high-performance or storage-sensitive applications.
Key takeaways
JSON should be avoided in scenarios where performance and storage efficiency are critical.
For applications prioritizing speed and data compactness, Protocol Buffers is the preferred format, particularly in latency-sensitive systems.
For data lakes and analytical workloads, Parquet or ORC are recommended due to their compression capabilities and columnar storage.
Avro remains a strong option for log processing and Kafka-based streaming systems, given its schema evolution support.
Emerging data formats
In addition to the widely adopted serialization formats discussed above, several emerging formats are gaining momentum across specific domains. These formats aim to balance performance, efficiency, and compatibility, often targeting niche use cases such as embedded systems, real-time communication, or document databases.
BSON (Binary JSON):NPrimarily used in MongoDB, BSON extends the JSON data model by incorporating support for additional data types, including binary and date formats. It enables more efficient storage and retrieval while preserving compatibility with JSON-based structures.
MessagePack: A compact binary serialization format that offers reduced data size without sacrificing processing speed. It is well-suited for network transmission and mobile or resource-constrained environments due to its lightweight nature.
CBOR (Concise Binary Object Representation): Designed for small-scale and embedded systems, CBOR provides efficient serialization of data structures with a focus on minimal footprint and processing overhead. It is commonly used in IoT applications.
UBJSON (Universal Binary JSON): Intended as a universal binary representation of JSON, UBJSON maintains close alignment with the JSON specification while offering improved performance and storage efficiency. It aims to provide a consistent, efficient alternative for systems that require binary serialization with JSON compatibility.
Conclusion
The growing demands of big data and performance-critical applications have highlighted the limitations of JSON, prompting the adoption of more efficient and specialized serialization formats. While JSON continues to be a practical choice for many scenarios, particularly where human readability and simplicity are valued, it is less suited to environments where scalability, speed, and storage optimization are critical.
By understanding the strengths and trade-offs of alternatives to JSON, such as Protocol Buffers, Avro, Parquet, and others, organizations can make more informed decisions that align with their technical and operational requirements. As data volumes and processing needs continue to increase, staying informed about evolving serialization technologies will be essential for maintaining effective and efficient data management practices.
Talk to us
Share this article
Author
NetRom Software
NetRom Software consists of a diverse team of domain experts and highly skilled developers based in Romania. With deep technical knowledge and hands-on experience, our specialists regularly share insights into software development, digital innovation, and industry best practices. By sharing our expertise, we aim to foster collaboration, transparency, and continuous improvement.