In today’s digital landscape, voice interaction has become an increasingly important method for users to engage with devices and applications. The ability to issue commands and receive responses through spoken language is transforming user experiences, offering a more natural and accessible interface.
Established virtual assistants such as Siri, Google Assistant, and Alexa have demonstrated the potential of voice-controlled technology. This shift is now extending into web applications, where voice-activated and hands-free features are moving beyond experimental stages to become practical solutions. As users grow more accustomed to interacting without traditional input methods like keyboards or touchscreens, the integration of voice interfaces is evolving from an optional enhancement to a functional requirement in many contexts.
Overview
Imagine a world where, instead of clicking through menus, a user simply says, “Show me the latest order entries” - and your web application delivers. It may sound like something out of a sci-fi movie, but voice-driven web experiences are becoming more attainable than ever, even if they sometimes risk crossing into overengineering.
In this article, we’ll guide you through the process of adding voice capabilities to your web application, enabling it to listen and respond with actions, powered by modern Speech Recognition APIs.
What is speech recognition?
In simple terms, speech recognition refers to a system’s ability to listen to and interpret a user’s spoken commands, enabling interaction without the need for typing. This creates more accessible and efficient ways to engage with technology. Speech recognition is widely used in virtual assistants, transcription services, and voice-controlled applications, offering a natural, intuitive user experience.
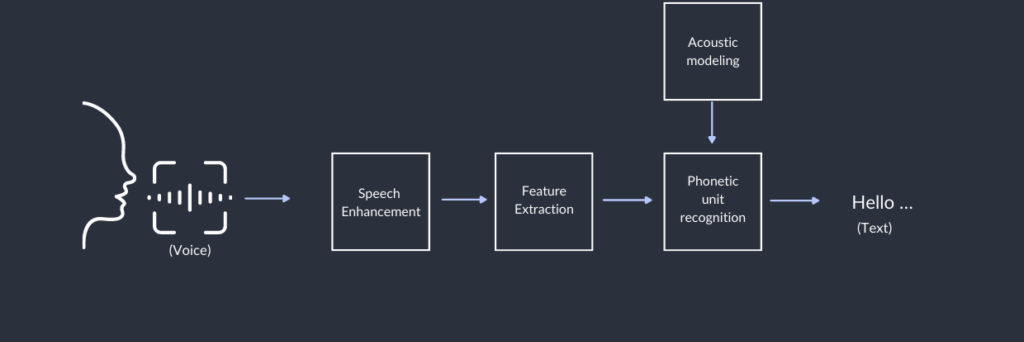
While the core technology behind voice recognition has been around for years, it has only recently gained widespread adoption, thanks to several key factors:
- Smartphones have acted as a catalyst, with growing mobile usage driving demand for faster, more natural interactions.
- Advances in technology have pushed speech recognition accuracy beyond 95%, making voice a viable and reliable alternative to text.
Web Speech API
The Web Speech API is one of the most powerful and widely used JavaScript APIs for adding voice interaction and speech synthesis features to web applications.
This API gives developers the tools to integrate both speech recognition and text-to-speech functionality, without needing to install extra drivers or plugins. For example, when a user speaks a command like “search for customer Allen Brown”, the API transcribes the spoken input into text, allowing your system to trigger specific actions based on that input.
The API consists of two main components:
- Speech recognition (speech-to-text): Converts spoken input into text. This is implemented through the SpeechRecognition interface, enabling your application to listen for and respond to voice commands.

- Speech synthesis (text-to-speech: Converts text into spoken output. This is implemented via the SpeechSynthesis interface, allowing your application to “speak” text back to the user.
Speech recognition use cases
Wondering where speech recognition fits into the business world? Here are some impactful ways this technology is transforming how companies interact with systems and data:
- Interactive search & navigation: Already a standard feature on most smartphones, voice-driven search allows users to speak their queries instead of typing. This is especially useful in hands-free scenarios or when users need to multitask while interacting with an application.
- Dictation & transcription: One of the most popular uses of speech recognition is converting spoken words into written text. For example, healthcare professionals can dictate patient reports, which are then transcribed into accurate electronic health records (EHRs), saving time and improving data quality.
- Sentiment analysis: Speech recognition goes beyond transcription. When combined with natural language processing (NLP), it can analyze the emotional tone of a conversation—identifying whether it’s positive, negative, or neutral—allowing systems to tailor their responses accordingly.
- Animal sound detection: Speech recognition technology isn’t limited to human voices. It can also be adapted to recognize and analyze animal sounds, supporting wildlife monitoring, migration tracking, and conservation efforts for endangered species.
- Voice authentication :Like a fingerprint or retina scan, a person’s voice can serve as a unique biometric identifier. Voice authentication enables secure access control, ensuring that only authorized users can access sensitive data or perform protected actions—whether opening medical records, unlocking rooms, or authorizing financial transactions.
Web Speech API: How it works
Simply put, the Web Speech API is an interface that listens to a user’s voice, interprets spoken commands, and triggers actions offering a more accessible, efficient way to interact with applications compared to typing.
But how does it work under the hood? Let’s break down the key steps:
- Browser compatibility: First, you need to make sure your app runs in a supported browser. As of now, the Web Speech API is still experimental, with official support mainly in Chrome (check current browser compatibility for updates).
- Voice capture: Using the SpeechRecognition interface, the system activates the device’s microphone and starts listening for audio input. For example, if the user says, “create invoice for customer Allen Brown”, the system records this command for processing.
- Speech recognition processing: Once the input is captured, the recognition service analyzes the audio based on speech features (such as a defined grammar). It then returns a result (in the form of a text string) and fires the onResult event.
- System response: After processing, the system extracts key words or phrases and triggers corresponding actions in your app. For example, if the recognized text includes “customer Allen Brown”, the system might automatically prefill or select a customer form field if that customer exists in your database.
Web Speech API:Challenges
While the Web Speech API provides a solid foundation with its two core features, it’s important to be aware of some key limitations:
- Accuracy issues with complex input: For simple, direct commands, the API performs well. However, when dealing with more complex phrases, it may struggle with transcription accuracy or formatting. Factors such as accents, background noise, or poor audio quality can further affect results.
- Limited browser support: Browser compatibility remains a challenge, as the API is still experimental and not universally supported across all browsers.
Despite these challenges, alternatives are available. Cloud-based APIs like Speechly, Google’s Speech-to-Text API, or Microsoft Azure Cognitive Speech Services offer robust, pre-built speech recognition solutions. These services provide straightforward API calls and can act as powerful bridges between user voice input and your web application.

Voice commands in web applications
Integrating voice commands into web applications can significantly enhance the user experience. Here are the key reasons to consider adding this feature:
- Improved accessibility: Voice commands make web applications more accessible to a wider range of users, enabling easier navigation and interaction with core features.
- Time-saving and efficiency: Voice input streamlines interactions, offering a hands-free way to work. This is especially useful for tasks like searching, issuing commands, or filling out forms. For example, users can search for customers, view invoices, read details, or even start tasks—without ever touching a keyboard, touchscreen, or mouse.
- Innovation: Adding voice command capabilities positions your application as modern and forward-thinking, helping you stay on trend and meet growing user expectations for interactive, voice-enabled experiences.
Conclusion
In conclusion, the integration of JavaScript with modern Speech Recognition APIs represents a major leap in technological innovation. If you still think voice-driven interaction isn’t mainstream, consider this: In 2018, 27% of the global online population used voice search on mobile devices, and by 2023, 41% of adults in the United States were using voice search daily.
Embracing voice-driven experiences is no longer just a trend—it’s becoming essential. Whether for boosting productivity, enhancing communication, or staying ahead of industry trends, shifting toward voice-enabled technologies will not only increase engagement but also provide users with more intuitive, dynamic, and accessible web experiences.

WebAssembly: Revolutionizing web development

WebSocket’s competition: MQTT vs WebRTC protocols
